Overview¶
Vision¶
RLPy is a framework for conducting sequential decision making experiments that involve value-function based approaches. It provides a modular toolbox, where various components can be linked together to create experiments.
The Big Picture¶
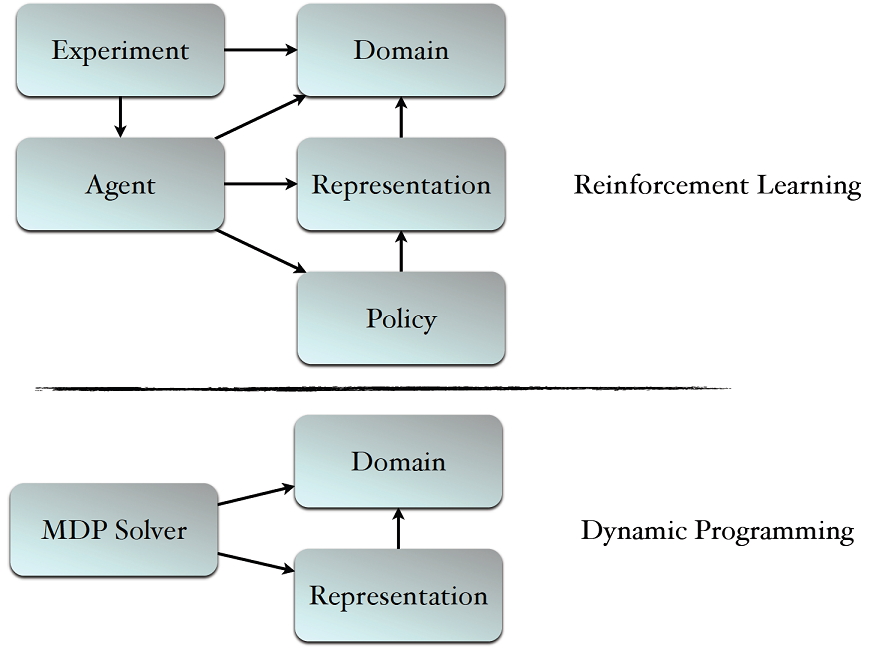
Reinforcement Learning (RL)¶
Setting up an RL experiment requires selecting the following 4 key components:
- Agent: This is the box where learning happens. It is often done by changing the weight vector corresponding to the features.
- Policy: This box is responsible to generate actions based on the current states. The action selection mechanism often dependends on the estimated value function.
- Representation: In this framework, we assume the use of linear function approximators to represent the value function. This box realizes the underlying representation used for capturing the value function. Note that the features used for approximation can be non-linear.
- Domain: This box is an MDP that we are interested to solve.
The Experiment class works as a glue that connect all these pieces together.
Dynamic Programming¶
If the full model of the MDP is known, Dynamic Programming techniques can be used to solve the MDP. To setup a DP experiment the following 3 components have to be set:
- MDP Solver: Dynamic programming algorithm
- Representation: Same as the RL case. Notice that the Value Iteration and Policy Iteration techniques can be only coupled with the tabular representation.
- Domain: Same as the RL case.
Note
Each of the components mentioned here has several realizations in RLPy, yet this website provides guidance only on the main abstract classes, namely: Agent, MDP Solver, Representation, Policy, Domain and Experiment
See also
The tutorial page provides simple 10-15 minutes examples on how various experiments can be setup and used.n
Acknowledgements¶
The project was partially funded by ONR and AFOSR grants.
Citing RLPy¶
If you use RLPy to conduct your research, please cite
Alborz Geramifard, Robert H Klein, Christoph Dann, William Dabney and Jonathan P How, RLPy: The Reinforcement Learning Library for Education and Research, 2013. http://acl.mit.edu/RLPy, April, 2013
Bibtex:
@ONLINE{RLPy,
author = {Alborz Geramifard and Robert H Klein and Christoph Dann and
William Dabney and Jonathan P How},
title = {{RLPy: The Reinforcement Learning Library for Education and Research}},
month = April,
year = {2013},
howpublished = {\url{http://acl.mit.edu/RLPy}},
}
Staying Connected¶
Feel free to join the rlpy list, rlpy@mit.edu, by clicking here. This list is intended for open discussion about questions, potential improvements, etc.